Organizing an event can be a full-time task in and of its own. I have been organizing ASA DataFest for six years at Duke, and over this time, the number of participants has grown from 23 students from Duke only, to 360 students from seven area schools this year!
First, a bit about ASA DataFest: ASA DataFest is a data “hackathon” for students around the U.S., Canada, and Germany (for now; this list has been growing each year). Students spend a weekend working in small teams, around the clock, to find insight and meaning in a large, messy, and rich data set. For almost all students, it is the most complex data they have encountered, and they push themselves to master new skills, resurrect forgotten knowledge, and bring everything they’ve got to compete for the honor of being declared the best by a panel of expert judges.
As an educator, statistician, and data scientist, growth in student interest in this event sounds fantastic to me. However, as the person responsible for running the event at Duke, it has also meant that for the couple months leading up to DataFest, I have almost an additional full-time job dealing with everything from student registrations to promoting the event to putting in food orders. While I have not found an R-based solution for ordering food (yet!), this year I incorporated R and R Markdown in my organization workflow for grabbing, processing, and reporting registration information.
This post highlights using Google Forms for data collection (e.g., registration), the googlesheets package to pull that data into R, and packages from the tidyverse to manipulate, summarise, and visualize that data. Then, we use RPubs for publishing documents to be shared with participants and other constituents.
Here is a list of all packages used in this article:
library(googlesheets)
library(tidyverse)
library(stringr)
library(DT)
library(knitr)In an effort to make it easier for others organizing DataFests to replicate my workflow, I have created a Google Drive containing all forms needed for registering participants and collecting information from consultants (mentors), and judges. I have also populated these forms with randomly generated names to showcase how these data are processed to yield the rosters and reports that are useful for organizing the event and disseminating registration information. All Google Forms mentioned can be found in the DataFest Organization Google Drive, which is available for public viewing. You can make a copy for your own use.
Additionally, all R scripts and R Markdown documents used to process these data are available on the datafest GitHub repo.
Team sign ups
If a group of students has already formed a team, it makes sense for them to sign up as a team to ensure that they use the same team name and that everyone registers at once. This Google Form is used to sign such students up.
One issue with registering each team as a single entry is that we end up with what we call “wide” data: each row represents a team, and within that row we have information on all students in that team. However for most practical purposes (counting participants, plotting distributions of years and majors, figuring out how many of each size t-shirt to order, etc.) we need the data to be in “long” format, where each row represents a student.
To accomplish this transformation, we first read the data in using the googlesheets package:
part_wide <- gs_title("DataFest [YEAR] @ [HOST] - Team Sign up (Responses)") %>%
gs_read()Then, we realize that the variable names are a mess since they come directly from questions on the Google form!
names(part_wide)## [1] "timestamp" "team_name" "last_name_1"
## [4] "first_name_1" "school_1" "tshirt_size_1"
## [7] "class_year_1" "major_1" "email_1"
## [10] "participation_1" "diet_1" "last_name_2"
## [13] "first_name_2" "school_2" "tshirt_size_2"
## [16] "class_year_2" "major_2" "email_2"
## [19] "participation_2" "diet_2" "last_name_3"
## [22] "first_name_3" "school_3" "tshirt_size_3"
## [25] "class_year_3" "major_3" "email_3"
## [28] "participation_3" "diet_3" "last_name_4"
## [31] "first_name_4" "school_4" "tshirt_size_4"
## [34] "class_year_4" "major_4" "email_4"
## [37] "participation_4" "diet_4" "last_name_5"
## [40] "first_name_5" "school_5" "tshirt_size_5"
## [43] "class_year_5" "major_5" "email_5"
## [46] "participation_5" "diet_5" "photo"Using stringr, we can get these variable names in concise snake_case shape:
names(part_wide) <- names(part_wide) %>%
str_replace(" of team member", "") %>%
str_replace(" in DataFest before", "") %>%
str_replace(" Check all that apply.", "") %>%
str_replace("Email address", "email") %>%
str_replace("Dietary restrictions", "diet") %>%
str_replace("Check if you agree", "photo") %>%
str_replace("\\:", "") %>%
str_replace("-", "") %>%
str_replace_all(" ", "_") %>%
tolower()We can see that things look a lot better now:
names(part_wide)## [1] "timestamp" "team_name" "last_name_1"
## [4] "first_name_1" "school_1" "tshirt_size_1"
## [7] "class_year_1" "major_1" "email_1"
## [10] "participation_1" "diet_1" "last_name_2"
## [13] "first_name_2" "school_2" "tshirt_size_2"
## [16] "class_year_2" "major_2" "email_2"
## [19] "participation_2" "diet_2" "last_name_3"
## [22] "first_name_3" "school_3" "tshirt_size_3"
## [25] "class_year_3" "major_3" "email_3"
## [28] "participation_3" "diet_3" "last_name_4"
## [31] "first_name_4" "school_4" "tshirt_size_4"
## [34] "class_year_4" "major_4" "email_4"
## [37] "participation_4" "diet_4" "last_name_5"
## [40] "first_name_5" "school_5" "tshirt_size_5"
## [43] "class_year_5" "major_5" "email_5"
## [46] "participation_5" "diet_5" "photo"Finally, then we use dplyr and tidyr to transform the data from wide to long:
participants <- part_wide %>%
select(-photo) %>%
gather(column, entry, last_name_1:diet_5, -timestamp, -team_name) %>%
mutate(person_in_team = str_match(column, "[0-9]")) %>%
mutate(column = str_replace(column, "_[0-9]", "")) %>%
spread(column, entry) %>%
filter(!is.na(last_name)) %>%
arrange(team_name, last_name, first_name) %>%
select(-person_in_team) %>%
select(timestamp, team_name, first_name, last_name, email, school,
class_year, major, participation, diet, tshirt_size) # reorderLet’s take a peek:
participants## # A tibble: 16 x 11
## timestamp team_name first_name last_name
## <chr> <chr> <chr> <chr>
## 1 4/2/2017 22:20:05 Bae's Theorem Adrienne Fuller
## 2 4/2/2017 22:20:05 Bae's Theorem Sylvia Hicks
## 3 4/2/2017 22:20:05 Bae's Theorem Toni Simpson
## 4 4/2/2017 22:20:05 Bae's Theorem Vicky Water
## 5 4/4/2017 1:03:26 Bayes Anatomy Meredith Gray
## 6 4/4/2017 1:03:26 Bayes Anatomy Derek Shepherd
## 7 4/3/2017 16:14:00 Fake iid's Carolyn Byrd
## 8 4/3/2017 16:14:00 Fake iid's Gordon Hawkins
## 9 4/3/2017 16:14:00 Fake iid's Cecilia Pittman
## 10 4/3/2017 16:14:00 Fake iid's Paul Rios
## 11 4/3/2017 16:14:00 Fake iid's Ryan Rose
## 12 3/31/2017 23:55:00 Passive Regression Amanda Boyd
## 13 3/31/2017 23:55:00 Passive Regression Rosa Fox
## 14 3/31/2017 23:55:00 Passive Regression Lucas Gonzales
## 15 4/1/2017 20:14:05 The Pit James Andrews
## 16 4/1/2017 20:14:05 The Pit Tom Lawrence
## # ... with 7 more variables: email <chr>, school <chr>, class_year <chr>,
## # major <chr>, participation <chr>, diet <chr>, tshirt_size <chr>We can now easily look for duplicates (sometimes students sign up twice or more times) or use these data to explore the various features of participants.
Individual sign-ups
If a student is wanting to participate in DataFest but they don’t have a team in mind, we ask them to fill out a brief survey where they answer questions about their background as well as how much time they are wanting to commit to DataFest, ranging from “I’m in it to win it” to “I’m more interested in the experience, and am not really sure if I’ll submit a final presentation.”
Sometimes students find a team and register with that team after having filled out this survey. These students should be removed from the list of those looking for teammates, though there is no easy way for them to do so in Google Forms (they can’t go back and remove their response).
However we can easily do this with an anti_join. Suppose this data frame is called looking, and remember that the earlier data frame of students registering with teams was called participants.
looking <- anti_join(looking, participants, by = "email")Then, the survey results are made available to the same students who are looking for teammates so that they can match up with others and form a team.
looking %>%
select(first_name, last_name, participation_level, class_year, major, school, participation_before, email) %>%
arrange(participation_level, class_year, major, school) %>%
datatable()Here we make use of the datatable function in the DT package to display the list of students in a pretty and easily sortable and searchable format.
Consultants and judges
Using a similar approach we can also grab, organize, and report lists of consultants and judges. All relevant code for this can be found in the datafest GitHub repo.
Participant summary
Now that we have our participant data in a tidy format, we can visualize distributions of majors, years, previous participation etc.
For example, we can count how many teams are participating from each school:
participants %>%
distinct(team_name, .keep_all = TRUE) %>%
count(school) %>%
arrange(desc(n))## # A tibble: 3 x 2
## school n
## <chr> <int>
## 1 Faber College 2
## 2 Port Chester University 2
## 3 Harrison University 1or visualize the distribution of class years per school:
ggplot(data = participants, aes(x = school, fill = class_year)) +
geom_bar(position = "fill") +
labs(title = "Schools and class years")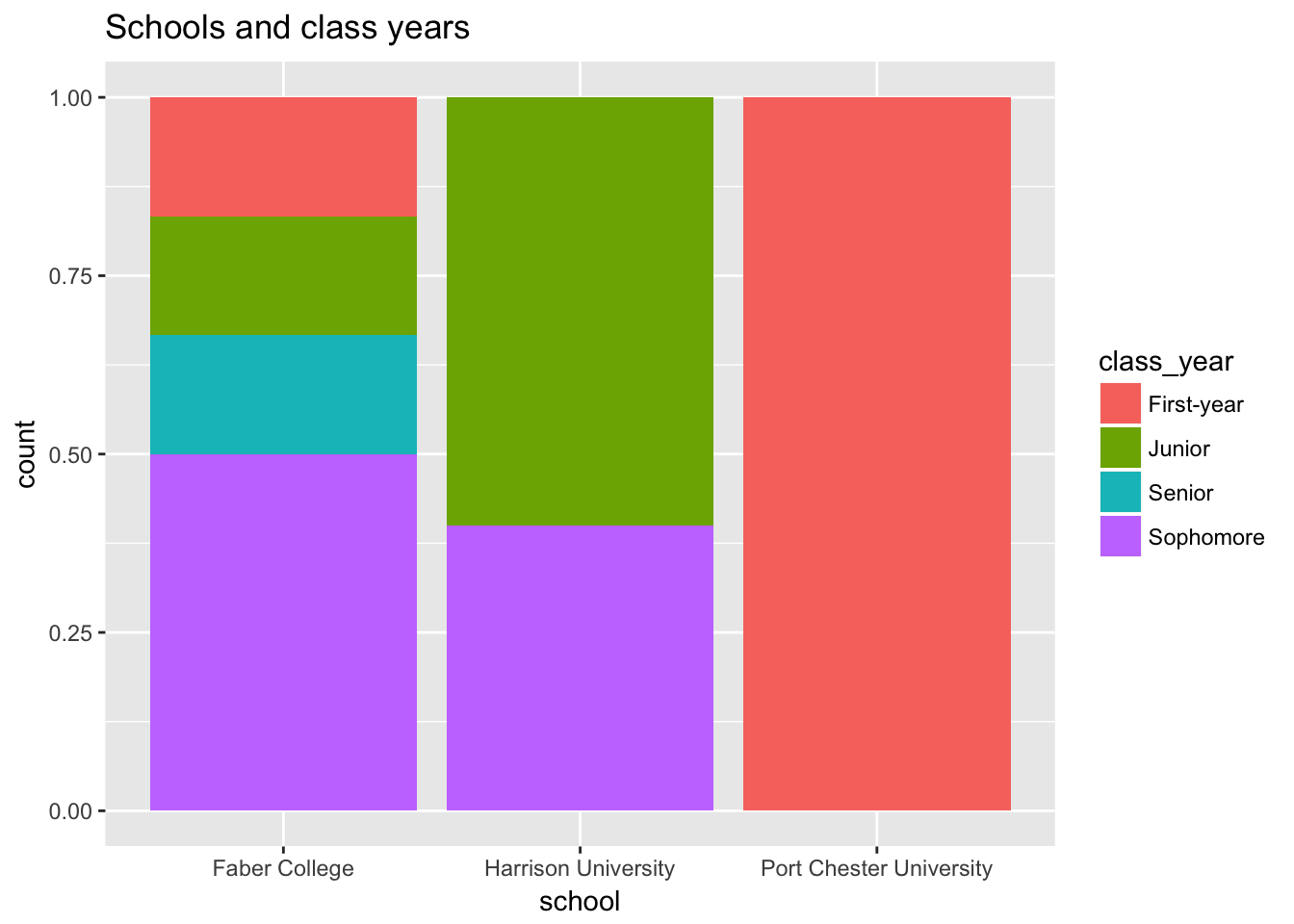
Information guides
We can also use R Markdown to create documents that are mostly text, that introduce the event to the participants, consultants, and judges. Then, summary statistics and visualizations of the participants can easily be included in these guides.
Sample guides for participants and consultants/judges can also be found on the GitHub repo.
And finally, all of these can be published on RPubs. However, note that these documents will be publicly available.
You may leave a comment below or discuss the post in the forum community.rstudio.com.