Note: This article is now several years old. If you have RStudio Connect, there are more modern ways of updating data in a Shiny app.
Shiny applications are often backed by fluid, changing data. Data updates can occur at different time scales: from scheduled daily updates to live streaming data and ad-hoc user inputs. This article describes best practices for handling data updates in Shiny, and discusses deployment strategies for automating data updates.
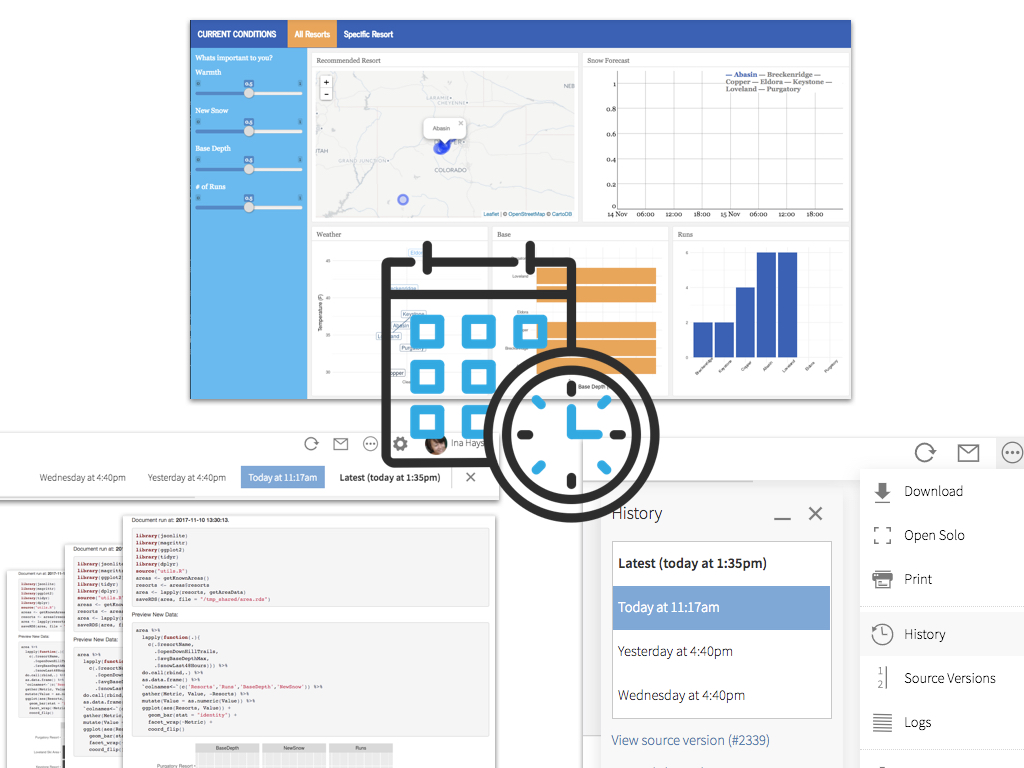
This post builds off of a 2017 rstudio::conf talk. The recording of the original talk and the sample code for this post are available.
The end goal of this example is a dashboard to help skiers in Colorado select a resort to visit. Recommendations are based on:
- Snow reports that provide useful metrics like number of runs open and amount of new snow. Snow reports are updated daily.
- Weather data, updated in near real-time from a live stream.
- User preferences, entered in the dashboard.
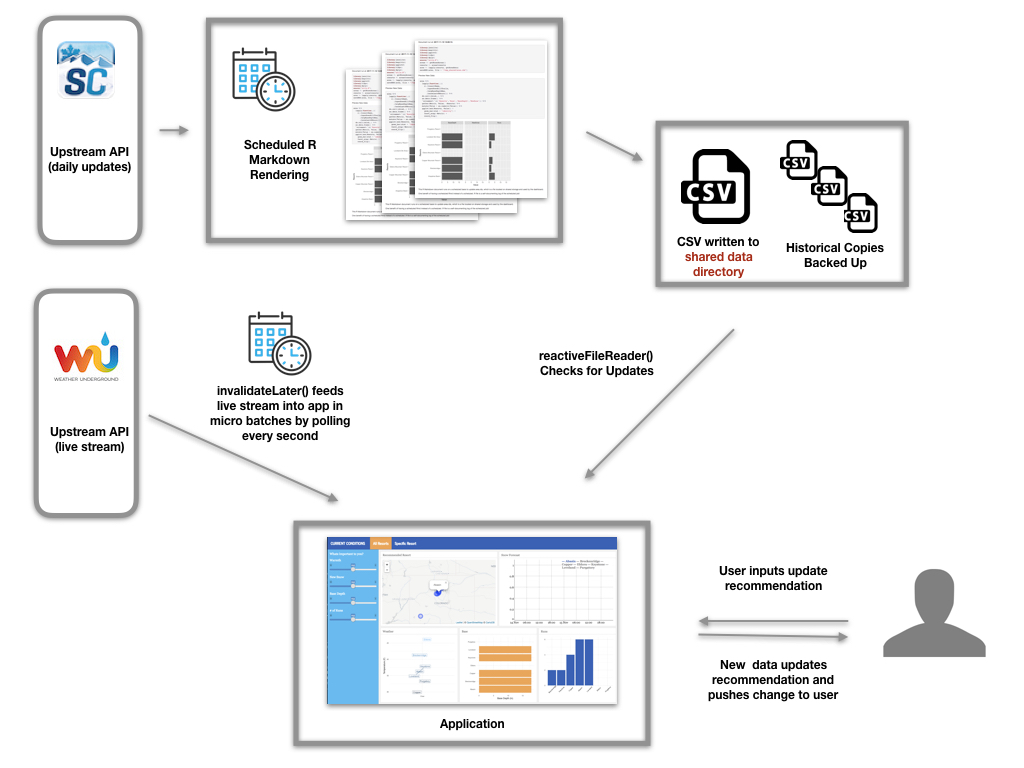
The backend for the dashboard looks like:
Automate Scheduled Data Updates
The first challenge is preparing the daily data. In this case, the data preparation requires a series of API requests and then basic data cleansing. The code for this process is written into an R Markdown document, alongside process documentation and a few simple graphs that help validate the new data. The R Markdown document ends by saving the cleansed data into a shared data directory. The entire R Markdown document is scheduled for execution.
It may seem odd at first to use a R Markdown document as the scheduled task. However, our team has found it incredibly useful to be able to look back through historical renderings of the “report” to gut-check the process. Using R Markdown also forces us to properly document the scheduled process.
We use RStudio Connect to easily schedule the document, view past historical renderings, and ultimately to host the application. If the job fails, Connect also sends us an email containing stdout from the render, which helps us stay on top of errors. (Connect can optionally send the successfully rendered report, as well.) However, the same scheduling could be accomplished with a workflow tool or even CRON.
Make sure the data, written to shared storage, is readable by the user running the Shiny application - typically a service account like rstudio-connect or shiny can be set as the run-as user to ensure consistent behavior.
Alternatively, instead of writing results to the file system, prepped data can be saved to a view in a database.
Using Scheduled Data in Shiny
The dashboard needs to look for updates to the underlying shared data and automatically update when the data changes. (It wouldn’t be a very good dashboard if users had to refresh a page to see new data.) In Shiny, this behavior is accomplished with the reactiveFileReader function:
daily_data <- reactiveFileReader(
intervalMillis = 100,
filePath = 'path/to/shared/data',
readFunc = readr::read_cs
)
The function checks the shared data file’s update timestamp every intervalMillis to see if the data has changed. If the data has changed, the file is re-read using readFunc. The resulting data object, daily_data, is reactive and can be used in downstream functions like render***.
If the cleansed data is stored in a database instead of written to a file in shared storage, use reactivePoll. reactivePoll is similar to reactiveFileReader, but instead of checking the file’s update timestamp, a second function needs to be supplied that identifies when the database is updated. The function’s help documentation includes an example.
Streaming Data
The second challenge is updating the dashboard with live streaming weather data. One way for Shiny to ingest a stream of data is by turning the stream into “micro-batches”. The invalidateLater function can be used for this purpose:
liveish_data <- reactive({
invalidateLater(100)
httr::GET(...)
})
This causes Shiny to poll the streaming API every 100 milliseconds for new data. The results are available in the reactive data object liveish_data. Picking how often to poll for data depends on a few factors:
- Does the upstream API enforce rate limits?
- How long does a data update take? The application will be blocked while it polls data.
The goal is to pick a polling time that balances the user’s desire for “live” data with these two concerns.
Conclusion
To summarize, this architecture provides a number of benefits: No more painful, manual running of R code every day! Dashboard code is isolated from data prep code. There is enough flexibility to meet user requirements for live and daily data, while preventing un-necessary number crunching on the backend.
You may leave a comment below or discuss the post in the forum community.rstudio.com.