It’s no secret that there are few industries more competitive than the pharmaceutical industry. Big money placed on long-shot bets for block-buster drugs where being first makes all the difference means a constant struggle to gain a competitive edge. So, you might find it surprising that the inaugural R / Pharma Conference held this past August on the Harvard campus in a very classy auditorium was all about collaboration.
Some might also find it surprising that data scientists from competitive companies would gather to share information, but this is quite common. I have seen it before in other competitive industries, for example in IEEE-led standards initiatives, where engineers gather to forge a common technology. Not only is there the human need to share and learn from peers (and also brag a little), there is a larger force at play: a kind of market clearing operation where experts gather to gain as much of an advantage as they can by ensuring that no easily exploitable arbitrage opportunities remain.
It was a surprise, though (and I think a source of general amusement as the conference proceeded), that nearly every talk seemed to be about Shiny. Looking back, it is clear that it should not have been: 49% of the abstracts explicitly mention Shiny. This word cloud was built from the abstract submissions.

Shiny is basically a technology for sharing complex information across multiple organizations and stakeholders with different skill sets. Shiny, too, is all about collaboration. For a look into the large, production-grade Shiny app, bioWARP, see Sebastian Wolf’s recent post.
Other major themes addressed at the conference were: reproducible research, package administration, scaling R for production, and using R in a regulatory environment. This last theme was underscored by a strong FDA presence. Lilliam Rosario from the FDA Center for Drug Evaluation & Research delivered the opening keynote, in which she addressed the regulatory role of CDER and the use of R. FDA speaker Mat Souktup spoke about the need to transcend the compartmentalized culture common in medical research, and how open-source tools are helpful in working towards this goal. He explicitly noted along the way that the FDA does not specify what software may be used. The third FDA speaker, Paul Schuette, filled in some details associated with topics raised by Rosario and talked about the use of R and Shiny at CDER. Along these same lines, Andy Nicholls from GSK conducted a well-attended and very informative workshop on The Challenges of Validating R. You can find Andy’s slides here.
Other keynote speakers were Max Kuhn, who talked about Modeling in the tidyverse (slides here); Joe Cheng, who described how to use Shiny responsibly in pharma (slides here); and Michael Lawrence, who spoke about enabling open-source analytics in the enterprise.
Slides for some of the other presentations made at the conference may be found here. I expect more will become available soon.
My very biased impression was that R / Pharma was an unqualified success at accomplishing the major objectives of bringing together data scientists and statisticians working in the Pharmaceutical industry, and of presenting a high quality program that explored several issues relating to the production use of R in a regulatory environment.
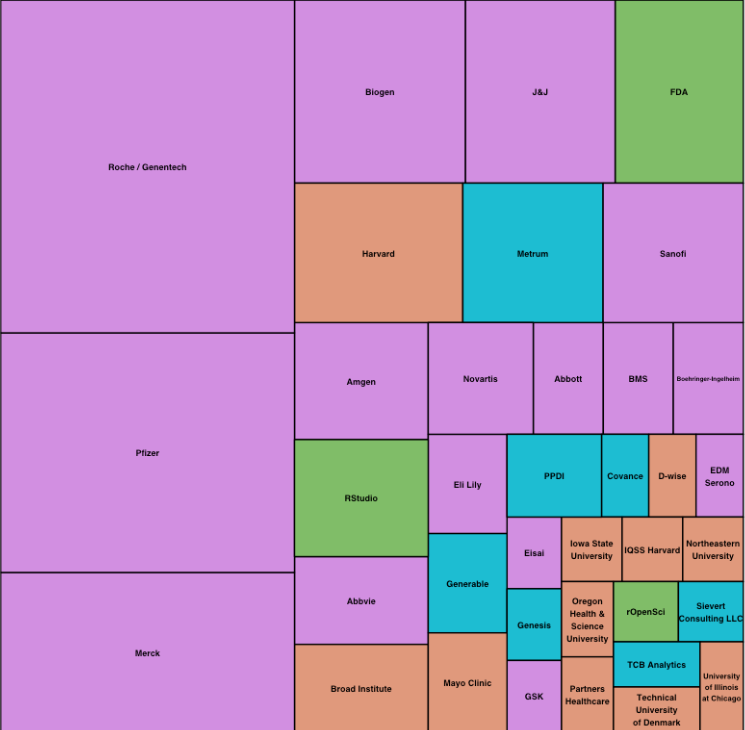
The following chart shows that representatives from quite a few pharmaceutical companies attended in spite of organization problems that artificially limited the overall number of attendees to about 140.
Planning has already begun for R / Pharma 2019. The exact date has not yet been locked in, but I expect it will be mid-August. Please stay tuned for more information.
You may leave a comment below or discuss the post in the forum community.rstudio.com.