Searching for R packages is a vexing problem for both new and experienced R users. With over 13,000 packages already on CRAN, and new packages arriving at a rate of almost 200 per month, it is impossible to keep up. Package names can be almost anything, and they are rarely informative, so searching by name is of little help. I make it a point to look at all of the new packages arriving on CRAN each month, but after a month or so, when asked about packages related to some particular topic, more often than not, I have little more to offer than a vague memory that I saw something that might be useful.
Fortunately, package developers have provided some very useful tools, if you know where to look. :) This post presents a search strategy based on some relatively new packages I have come across in my monthly review.
library(tidyverse)## ── Attaching packages ───────────────────────────────────────────── tidyverse 1.2.1 ──## ✔ ggplot2 2.2.1 ✔ purrr 0.2.4
## ✔ tibble 1.4.2 ✔ dplyr 0.7.5
## ✔ tidyr 0.8.1 ✔ stringr 1.3.1
## ✔ readr 1.1.1 ✔ forcats 0.3.0## ── Conflicts ──────────────────────────────────────────────── tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()library(packagefinder)
library(dlstats)
library(cranly)packagefinder v0.0.7, which appeared on CRAN this past July, goes right to the heart of the problem and shows great promise. The function findPackage() allows you to do a keyword search through the metadata of all CRAN packages. Since I am researching a possible post on Permutation Tests, I thought I would give packagefinder::findPackage() the most straightforward search text I could think of. (Note that the link for Permutation Tests above goes to an example by Thomas Leeper that references the coin package. This is a pretty strong hint that I expect to find coin prominently listed among the results.)
Also note, that making the output a tibble is not just obsessive-compulsive tidy behavior. The default print method sends the output to the Viewer in the RStudio IDE.
pt_pkg <- as.tibble(findPackage("permutation test"))##
## 59 out of 13256 CRAN packages found in 6 seconds.pt_pkg## # A tibble: 59 x 5
## SCORE NAME DESC_SHORT DOWNL_TOTAL GO
## <dbl> <chr> <chr> <S3: format> <fct>
## 1 100 permutes Permutation Tests for Time Series … NA 8300
## 2 75 AUtests Approximate Unconditional and Perm… NA 502
## 3 75 jmuOutlier Permutation Tests for Nonparametri… NA 5564
## 4 75 lmPerm Permutation Tests for Linear Models NA 6083
## 5 75 NetRep Permutation Testing Network Module… NA 7453
## 6 75 perm Exact or Asymptotic permutation te… NA 8289
## 7 75 permDep Permutation Tests for General Depe… NA 8292
## 8 75 permuco "Permutation Tests for Regression,… NA 8297
## 9 75 RATest Randomization Tests NA 9287
## 10 75 treeperm Exact and Asymptotic K Sample Perm… NA 12442
## # ... with 49 more rowsUnfortunately, the package is very new and not well-documented. It is not clear how SCORE is computed, and DOWNL_TOTAL is replete with NAs. Nevertheless, the function does seem to find packages. I can’t vouch for its completeness, but when I tried it out on some topics with which it I am familiar, it did a pretty thorough job. Note that findPackage() allows a user to set a weights parameter that affects how the search “hits in the package’s title, short description and long description”. So far, I have not found this to be particularly useful, but I have not spent a lot of time with it, either.
The next line of code just selects the columns we will be using.
pt_pkg <- select(pt_pkg, NAME, DESC_SHORT)Now that we have a list of packages of interest, it would be nice to have an indication of the quality and usefulness of the packages selected. A natural measure of usefulness is the number of times the package has been downloaded. For this, we turn to the cran_stats() function from the dlstats package. This function takes a vector of packages names as inputs, queries the RStudio download logs, and returns a data frame listing the number of downloads by month for each package.
pt_downloads <- cran_stats(pt_pkg$NAME)
dim(pt_downloads)## [1] 2784 4head(pt_downloads)## start end downloads package
## 4485 2018-05-01 2018-05-31 52 permutes
## 4544 2018-06-01 2018-06-30 89 permutes
## 4603 2018-07-01 2018-07-31 92 permutes
## 4662 2018-08-01 2018-08-31 74 permutes
## 4721 2018-09-01 2018-09-30 227 permutes
## 4780 2018-10-01 2018-10-22 142 permutesJust a little wrangling yields a data frame that lists total downloads for each package over its lifespan.
top_downloads <- pt_downloads %>% group_by(package) %>%
summarize(downloads = sum(downloads)) %>%
arrange(desc(downloads))
head(top_downloads,10)## # A tibble: 10 x 2
## package downloads
## <fct> <int>
## 1 coin 1103426
## 2 exactRankTests 137674
## 3 RVAideMemoire 108837
## 4 perm 97071
## 5 logcondens 83033
## 6 HardyWeinberg 55735
## 7 biotools 47694
## 8 smacof 45257
## 9 SNPassoc 38920
## 10 broman 30956As expected, coin has flipped to the head of the list. Plotting the downloads over time shows that the package has increased in popularity over the past five years, and it looks like people have been doing a crazy amount of permutation testing over the past year or so.
top_pkgs <- pt_downloads %>% filter(package %in% top_downloads$package[1:3])
ggplot(top_pkgs, aes(end, downloads, group=package, color=package)) +
geom_line() + geom_point(aes(shape=package))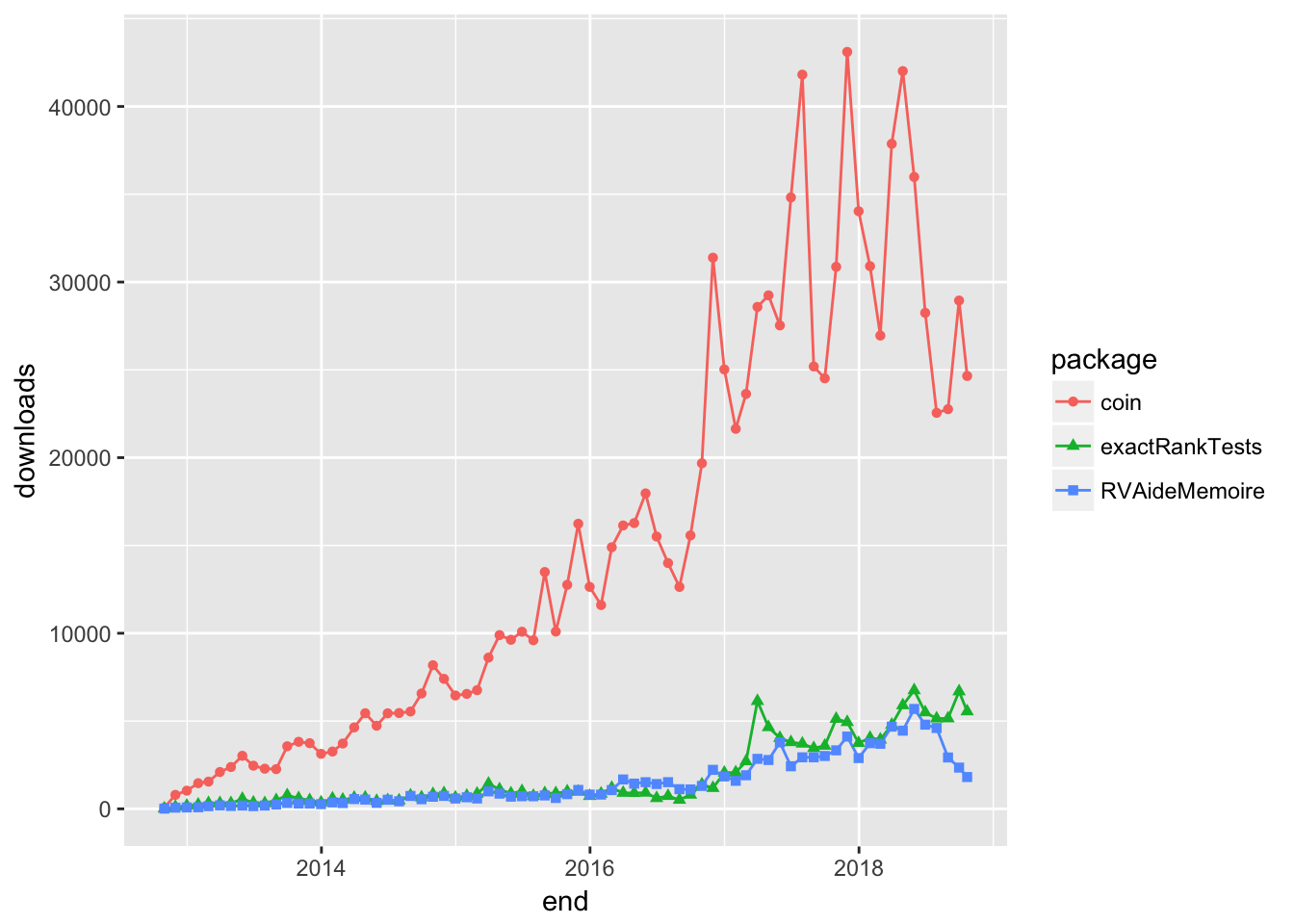
One way to gauge the quality and reliability of a package is to see how many other packages depend on it. These would be the packages listed as “Reverse depends” and “Reverse imports” on the CRAN page for a package. Using the canonical link, https://cran.r-project.org/package=coin, we see that 24 packages are listed in these fields on the coin page.
Likewise, knowing something of an author’s background, his or her experience writing other R packages, and prominent R developers he or she may have collaborated with is also helpful in assessing whether to give a newly found package is worth a try. The same link above also shows the package’s authors. Checking the Contributors page for the R Project, we see that two authors are members of R Core and the lead author, Torsten Hothorn, is listed with the contributors who have provided “invaluable help”. The background and collaborators couldn’t be better.
In most cases, background checks aren’t so easy. However, with the help of the build_network() function from the cranly package, it is simple to track down an author’s collaboration network. Here, we see that Torston has an extensive network of collaborators.
p_db <- tools::CRAN_package_db()
clean_p_db <- clean_CRAN_db(p_db)
author_net <- build_network(object = clean_p_db, perspective = "author")
plot(author_net, author = "Torsten Hothorn", exact = FALSE)It is also helpful to know who the most prolific CRAN package authors are. You can generally count on packages from this crew being top-shelf.
author_summary <- summary(author_net)## Warning in closeness(cranly_graph, normalized = FALSE): At centrality.c:
## 2784 :closeness centrality is not well-defined for disconnected graphsplot(author_summary)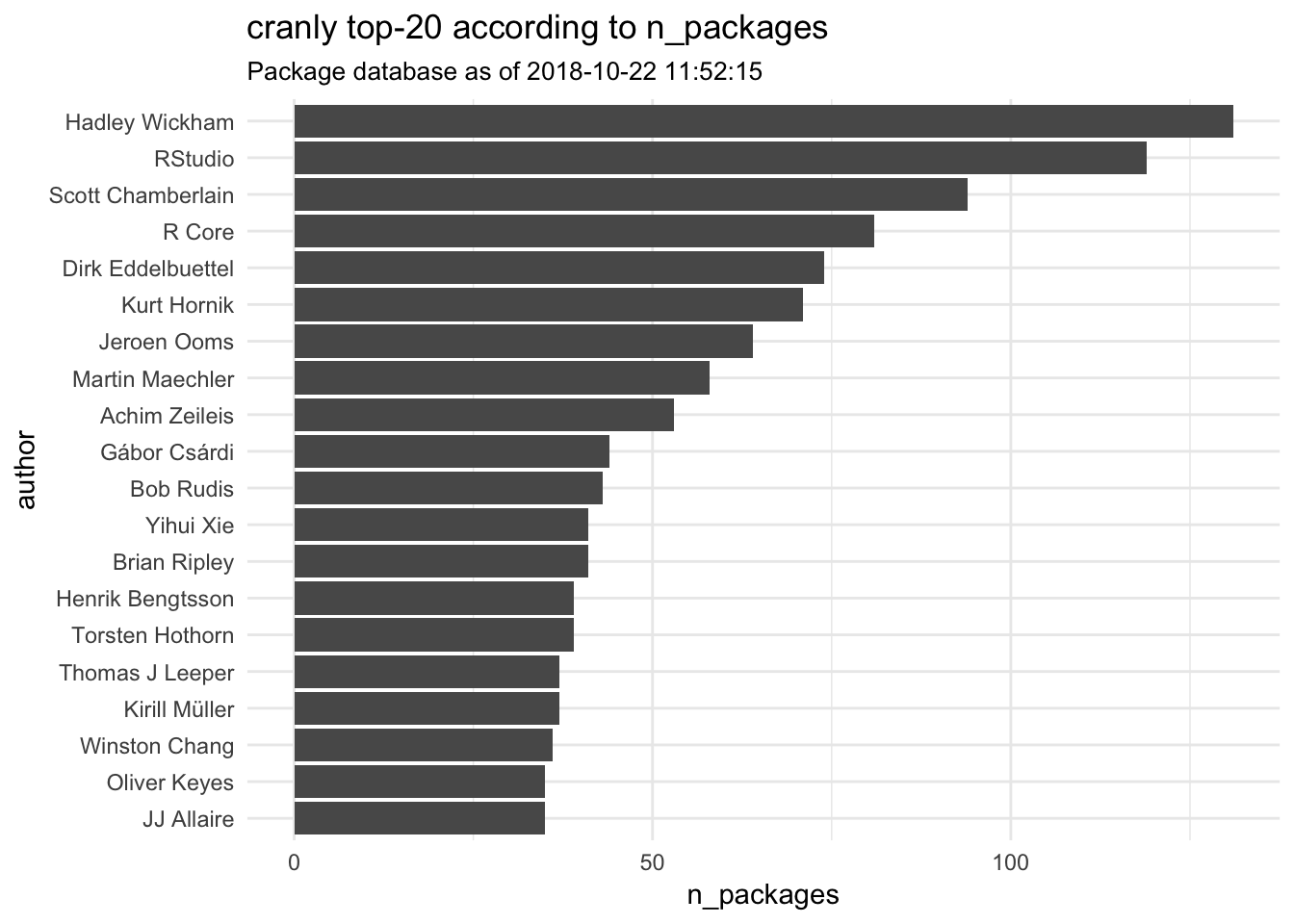
I am not claiming that the path I have taken here is the best, or even unique. I have by no means exhausted the possibilities with the packages I have highlighted. Previous posts explore cranly and the tools::CRAN_package_db() function in a little more depth, but there is much more to explore.
Finally, it would be remiss of me not to mention that the first thing anyone, novice or expert, should do when looking for a package to solve some new problem, or even to get an indication of the quality of a package, is to examine the CRAN Task Views. These are lists of packages curated by experts and organized into functional areas. With just a little searching, you will see that coin shows up in multiple task views.
You may leave a comment below or discuss the post in the forum community.rstudio.com.