Today, we continue our work on sampling so that we can run models on subsets of our data and then test the accuracy of the models on data not included in those subsets. In the machine learning prediction world, these two data sets are often called training data and testing data, but we’re not going to do any machine learning prediction today. We’ll stay with our good’ol Fama French regression models for the reasons explained last time: the goal is to explore a new method of sampling our data and I prefer to do that in the context of a familiar model and data set. In 2019, we’ll start expanding our horizons to different models and data, but for today it’s more of a tools exploration.
Loyal readers of this blog (if that’s you, thank you!) will remember that we undertook a similar project in the previous post, when we used k-fold cross-validation. Today, we will use rolling origin sampling of the data, which differs from k-fold cross-validation in the sense that with rolling origin we explicitly sample based on the dates of our observation. With rolling origin, our first sample starts on the first day, our second sample starts on the second day, our third sample starts on third day. Or, we could have the second sample start on the twentieth day, or we could have it start again on the first day and just include an extra day. Either way, we are aware of the order of our data when sampling. With k-fold cross-validation, we were randomly shuffling and then selecting observations. This distinction can be particularly important for economic time series where we believe that the order of our observations is important.
Let’s get to it.
First, we need our data and, as usual, we’ll import data for daily prices of 5 ETFs, convert them to returns (have a look here for a refresher on that code flow), then import the 5 Fama French factor data and join it to our 5 ETF returns data. Here’s the code to make that happen (this code was covered in detail in this post:
library(tidyverse)
library(tidyquant)
library(rsample)
library(broom)
library(timetk)
symbols <- c("SPY", "EFA", "IJS", "EEM", "AGG")
# The prices object will hold our daily price data.
prices <-
getSymbols(symbols, src = 'yahoo',
from = "2012-12-31",
to = "2017-12-31",
auto.assign = TRUE,
warnings = FALSE) %>%
map(~Ad(get(.))) %>%
reduce(merge) %>%
`colnames<-`(symbols)
asset_returns_long <-
prices %>%
tk_tbl(preserve_index = TRUE, rename_index = "date") %>%
gather(asset, returns, -date) %>%
group_by(asset) %>%
mutate(returns = (log(returns) - log(lag(returns)))) %>%
na.omit()
factors_data_address <-
"http://mba.tuck.dartmouth.edu/pages/faculty/ken.french/ftp/Global_5_Factors_Daily_CSV.zip"
factors_csv_name <- "Global_5_Factors_Daily.csv"
temp <- tempfile()
download.file(
# location of file to be downloaded
factors_data_address,
# where we want R to store that file
temp,
quiet = TRUE)
Global_5_Factors <-
read_csv(unz(temp, factors_csv_name), skip = 6 ) %>%
rename(date = X1, MKT = `Mkt-RF`) %>%
mutate(date = ymd(parse_date_time(date, "%Y%m%d")))%>%
mutate_if(is.numeric, funs(. / 100)) %>%
select(-RF)
data_joined_tidy <-
asset_returns_long %>%
left_join(Global_5_Factors, by = "date") %>%
na.omit()After running that code, we have an object called data_joined_tidy. It holds daily returns for 5 ETFs and the Fama French factors. Here’s a look at the first row for each ETF rows.
data_joined_tidy %>%
slice(1)# A tibble: 5 x 8
# Groups: asset [5]
date asset returns MKT SMB HML RMW CMA
<date> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2013-01-02 AGG -0.00117 0.0199 -0.0043 0.0028 -0.0028 -0.0023
2 2013-01-02 EEM 0.0194 0.0199 -0.0043 0.0028 -0.0028 -0.0023
3 2013-01-02 EFA 0.0154 0.0199 -0.0043 0.0028 -0.0028 -0.0023
4 2013-01-02 IJS 0.0271 0.0199 -0.0043 0.0028 -0.0028 -0.0023
5 2013-01-02 SPY 0.0253 0.0199 -0.0043 0.0028 -0.0028 -0.0023For today, let’s work with just the daily returns of EEM.
eem_for_roll <- data_joined_tidy %>%
filter(asset == "EEM")We are going to regress those EEM daily returns on the Fama French factors and need a way to measure the accuracy of our various factor models. Previously, we measured our models by looking at the adjusted R-squared, when the models were run on the entirety of the data. Last time, we use k-fold cross-validation to split the data into a bunch of subsets, then ran our model on the subsets and measured the accuracy against the holdouts from the subsets. Now, let’s use the rolling_origin() function from rsample to split our data into analysis and assessment sets in a time-aware way, then calculate RMSEs.
The rolling_origin() function needs a few arguments set. We first set data to be eem_for_roll Then, we assign initial to be 50 - this tells the function that the size of our first sample is 50 days. Our first chunk of analysis data will be the first 50 days of EEM returns. Next, we assign assess to be 5 - this tells the function that our assessment data is the 5 days of EEM returns following those first 50 days. Finally, we set cumulative to be FALSE - this tells the functions that each of splits is a 50 days. The first split is the first 50 days, starting on day 1 and ending on day 50. The next split starts on day 2 and ends on day 51. If we were to set cumulative = TRUE, the first split would be 50 days. The next split would be 51 days, the next split would be 52 days. And so on. The analysis split days would be accumulating. For now, we will leave it at cumulative = FALSE.
For that reason, we will append _sliding to the name of our object because the start of our window will slide each time.
library(rsample)
roll_eem_sliding <-
rolling_origin(
data = eem_for_roll,
initial = 50,
assess = 10,
cumulative = FALSE
)Look at an individual split.
one_eem_split <-
roll_eem_sliding$splits[[1]]
one_eem_split<50/10/1259>That 50 is telling us there are 50 days or rows in the analysis set; that 10 is telling us that there are 10 rows in our assessment data - we’ll see how well our model predicts the return 5 days after the last observation in our data.
Here is the analysis subset of that split.
analysis(one_eem_split) %>%
head()# A tibble: 6 x 8
# Groups: asset [1]
date asset returns MKT SMB HML RMW CMA
<date> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2013-01-02 EEM 0.0194 0.0199 -0.0043 0.0028 -0.0028 -0.0023
2 2013-01-03 EEM -0.00710 -0.0021 0.00120 0.000600 0.0008 0.0013
3 2013-01-04 EEM 0.00200 0.0064 0.0011 0.0056 -0.0043 0.0036
4 2013-01-07 EEM -0.00759 -0.0014 0.00580 0 -0.0015 0.0001
5 2013-01-08 EEM -0.00900 -0.0027 0.0018 -0.00120 -0.0002 0.00120
6 2013-01-09 EEM 0.00428 0.0036 0.000300 0.0025 -0.0028 0.001 And the assessment subset - this is 10 rows.
assessment(one_eem_split)# A tibble: 10 x 8
# Groups: asset [1]
date asset returns MKT SMB HML RMW CMA
<date> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2013-03-15 EEM -0.00908 0.0025 0.006 -0.0001 0.0018 -0.0001
2 2013-03-18 EEM -0.0113 -0.0093 0.0021 -0.0039 0.0039 -0.001
3 2013-03-19 EEM -0.00712 -0.003 0.0015 -0.0023 0.0017 0.0028
4 2013-03-20 EEM 0.00570 0.0052 -0.003 0.0023 -0.002 0.002
5 2013-03-21 EEM -0.0102 -0.0037 0.0085 -0.0007 0.00120 0.0008
6 2013-03-22 EEM 0.00382 0.0033 -0.0042 -0.0023 0.0022 -0.0007
7 2013-03-25 EEM -0.000954 -0.0037 0.0036 -0.0032 0.0027 0.000600
8 2013-03-26 EEM 0.0142 0.0039 -0.0032 -0.0017 0.00120 -0.0017
9 2013-03-27 EEM 0.00376 -0.0016 0.0022 -0.0004 -0.0002 -0.0008
10 2013-03-28 EEM 0.00211 0.0033 -0.0022 -0.0031 0.000600 0.000600By way of comparison, here’s what the k-fold cross-validated data would look like.
cved_eem <-
vfold_cv(eem_for_roll, v = 5)
assessment(cved_eem$splits[[1]]) %>%
head()# A tibble: 6 x 8
# Groups: asset [1]
date asset returns MKT SMB HML RMW CMA
<date> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2013-01-04 EEM 0.00200 0.0064 0.0011 0.0056 -0.0043 0.0036
2 2013-01-14 EEM 0.00426 -0.000600 0.0002 0.0013 -0.001 0.0011
3 2013-01-31 EEM 0.00204 -0.0021 0.0038 0.000300 -0.0007 -0.0001
4 2013-02-04 EEM -0.0133 -0.0107 0.0059 -0.0027 0.0023 0.0004
5 2013-02-05 EEM 0.00114 0.0034 -0.0054 -0.0002 0.0008 -0.002
6 2013-02-06 EEM -0.00114 0.0019 0.0037 0.0022 -0.0018 0.0028Notice how the first date is not necessarily the first date in our data. In fact, if you run that code chunk a few times, the first date will be randomly selected. For me, it varied between January 2nd and January 15th.
Back to our rolling_origin data, we know that split 1 begins on day 1 and ends on day 50:
analysis(roll_eem_sliding$splits[[1]]) %>%
slice(c(1,50))# A tibble: 2 x 8
# Groups: asset [1]
date asset returns MKT SMB HML RMW CMA
<date> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2013-01-02 EEM 0.0194 0.0199 -0.0043 0.0028 -0.0028 -0.0023
2 2013-03-14 EEM 0.00418 0.0078 0.0021 0.0016 -0.002 0.0026And we know split 2 begins on day 2 and ends on day 51:
analysis(roll_eem_sliding$splits[[2]]) %>%
slice(c(1,50))# A tibble: 2 x 8
# Groups: asset [1]
date asset returns MKT SMB HML RMW CMA
<date> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2013-01-03 EEM -0.00710 -0.0021 0.00120 0.000600 0.0008 0.0013
2 2013-03-15 EEM -0.00908 0.0025 0.006 -0.0001 0.0018 -0.0001Now, we can start using our data to fit and then assess our model. The code flow is very similar to our previous post, but I’ll go ahead and run through it anyway.
First, let’s create a function that takes a split as an argument, fits a 3-factor Fama French model and calculates the root mean squared error. We will use the rmse() function from yardstick to measure our model. RMSE stands for root mean-squared error. It’s the sum of the squared differences between our fitted values and the actual values in the assessment data. A lower RMSE is better!
library(yardstick)
ff_three_rmse <- function(split){
analysis_set <- analysis(split)
ff_model <- lm(returns ~ MKT + SMB + HML , data = analysis_set)
holdout <- assessment(split)
rmse <-
ff_model %>%
augment(newdata = holdout) %>%
rmse(returns, .fitted) %>%
pull(.estimate)
}Let’s pass our one split object one_eem_split to the function.
ff_three_rmse(one_eem_split) %>%
print()[1] 0.005311276Now, we can use mutate() and map_dbl() to pass all of our splits held in roll_eem_sliding to the function. This will return an rmse for this model when applied to each of our rolling origin splits. This takes a few seconds to run.
rmse_one_model <-
roll_eem_sliding %>%
mutate(model = map_dbl(
.x = splits,
.f = ~(ff_three_rmse(.x))))
rmse_one_model %>%
head()# A tibble: 6 x 3
splits id model
* <list> <chr> <dbl>
1 <split [50/10]> Slice0001 0.00531
2 <split [50/10]> Slice0002 0.00621
3 <split [50/10]> Slice0003 0.00642
4 <split [50/10]> Slice0004 0.00647
5 <split [50/10]> Slice0005 0.00654
6 <split [50/10]> Slice0006 0.00649This is the same as we did last time. Now, let’s get functional. We will define three models that we wish to test with via our rolling origin splits and RMSE, then pass those models to one function.
First, we use as.formula() to define our three models.
mod_form_1 <- as.formula(returns ~ MKT)
mod_form_2 <- as.formula(returns ~ MKT + SMB + HML)
mod_form_3 <- as.formula(returns ~ MKT + SMB + HML + RMW + CMA)We write one function that takes split as an argument, same as above, but also takes formula as an argument, so we can pass it different models. This gives us the flexibility to more easily define new models and pass them to map so I’ll append _flex to the name of this function.
ff_rolling_flex <- function(split, formula) {
split_for_data <- analysis(split)
ff_model <- lm(formula, data = split_for_data)
holdout <- assessment(split)
rmse <-
ff_model %>%
augment(newdata = holdout) %>%
rmse(returns, .fitted) %>%
pull(.estimate)
}
rmse_model_1_flex <-
roll_eem_sliding %>%
mutate(model_1_rmse = map_dbl(roll_eem_sliding$splits,
ff_rolling_flex,
formula = mod_form_1))
rmse_model_1_flex %>%
head()# A tibble: 6 x 3
splits id model_1_rmse
* <list> <chr> <dbl>
1 <split [50/10]> Slice0001 0.00601
2 <split [50/10]> Slice0002 0.00548
3 <split [50/10]> Slice0003 0.00547
4 <split [50/10]> Slice0004 0.00556
5 <split [50/10]> Slice0005 0.00544
6 <split [50/10]> Slice0006 0.00539Again same as last time, we can run all of our models using the mutate() and map_dbl combination. Warning, this one takes a bit of time and compute to run - proceed with caution if you’re on a desktop.
rmse_3_models <-
roll_eem_sliding %>%
mutate(model_1_rmse = map_dbl(roll_eem_sliding$splits,
ff_rolling_flex,
formula = mod_form_1),
model_2_rmse = map_dbl(roll_eem_sliding$splits,
ff_rolling_flex,
formula = mod_form_2),
model_3_rmse = map_dbl(roll_eem_sliding$splits,
ff_rolling_flex,
formula = mod_form_3))
rmse_3_models %>%
head()# A tibble: 6 x 5
splits id model_1_rmse model_2_rmse model_3_rmse
* <list> <chr> <dbl> <dbl> <dbl>
1 <split [50/10]> Slice0001 0.00601 0.00531 0.00496
2 <split [50/10]> Slice0002 0.00548 0.00621 0.00596
3 <split [50/10]> Slice0003 0.00547 0.00642 0.00617
4 <split [50/10]> Slice0004 0.00556 0.00647 0.00615
5 <split [50/10]> Slice0005 0.00544 0.00654 0.00613
6 <split [50/10]> Slice0006 0.00539 0.00649 0.00600Alright, we have our RMSE, from each of our 3 models, as applied to each of our splits.
Thus far, our substantive flow is very similar to our k-fold cross-validation work. But now, we can take advantage of the time-aware nature of our splits.
Let’s visualize how our RMSE has changed over different time-aware splits, for our various models. Remember, we know the exact start and end date for our analysis and assessment sets, so we can extract the date of, say the first observation in the assessment data and assign it to the split. We can consider this the date of that model run.
First, let’s create a function to extract the first date of each of our assessment sets.
get_start_date <- function(x)
min(assessment(x)$date)Here’s how that works on our one split object.
get_start_date(one_eem_split)[1] "2013-03-15"That’s the first date in the assessment data:
assessment(one_eem_split) %>%
select(date) %>%
slice(1)# A tibble: 1 x 2
# Groups: asset [1]
asset date
<chr> <date>
1 EEM 2013-03-15We want to add a column to our results_3 object called start_date. We’ll use our usual mutate() and then map() flow to apply the get_start_date() function to each of our splits, but we’ll need to pipe the result to reduce(c) to coerce the result to a date. map() returns a list by default and we want a vector of dates.
rmse_3_models_with_start_date <-
rmse_3_models %>%
mutate(start_date = map(roll_eem_sliding$splits, get_start_date) %>% reduce(c)) %>%
select(start_date, everything())
rmse_3_models_with_start_date %>%
head()# A tibble: 6 x 6
start_date splits id model_1_rmse model_2_rmse model_3_rmse
* <date> <list> <chr> <dbl> <dbl> <dbl>
1 2013-03-15 <split [50/10]> Slice… 0.00601 0.00531 0.00496
2 2013-03-18 <split [50/10]> Slice… 0.00548 0.00621 0.00596
3 2013-03-19 <split [50/10]> Slice… 0.00547 0.00642 0.00617
4 2013-03-20 <split [50/10]> Slice… 0.00556 0.00647 0.00615
5 2013-03-21 <split [50/10]> Slice… 0.00544 0.00654 0.00613
6 2013-03-22 <split [50/10]> Slice… 0.00539 0.00649 0.00600We can head to ggplot for some visualizing. I’d like to plot all of my RMSE’s in different colors and the best way to do that is to gather() this data to tidy format, with a column called model and a column called value. It’s necessary to coerce to a data frame first, using as.data.frame().
rmse_3_models_with_start_date %>%
as.data.frame() %>%
select(-splits, -id) %>%
gather(model, value, -start_date) %>%
head() start_date model value
1 2013-03-15 model_1_rmse 0.006011868
2 2013-03-18 model_1_rmse 0.005483091
3 2013-03-19 model_1_rmse 0.005470834
4 2013-03-20 model_1_rmse 0.005557170
5 2013-03-21 model_1_rmse 0.005439921
6 2013-03-22 model_1_rmse 0.005391862Next, we can use some of our familiar ggplot methods to plot our RMSEs over time, and see if we notice this model degrading or improving in different periods.
rmse_3_models_with_start_date %>%
as.data.frame() %>%
select(-splits, -id) %>%
gather(model, value, -start_date) %>%
ggplot(aes(x = start_date, y = value, color = model)) +
geom_point() +
facet_wrap(~model, nrow = 2) +
scale_x_date(breaks = scales::pretty_breaks(n = 10)) +
theme(axis.text.x = element_text(angle = 45, vjust = 1, hjust=1))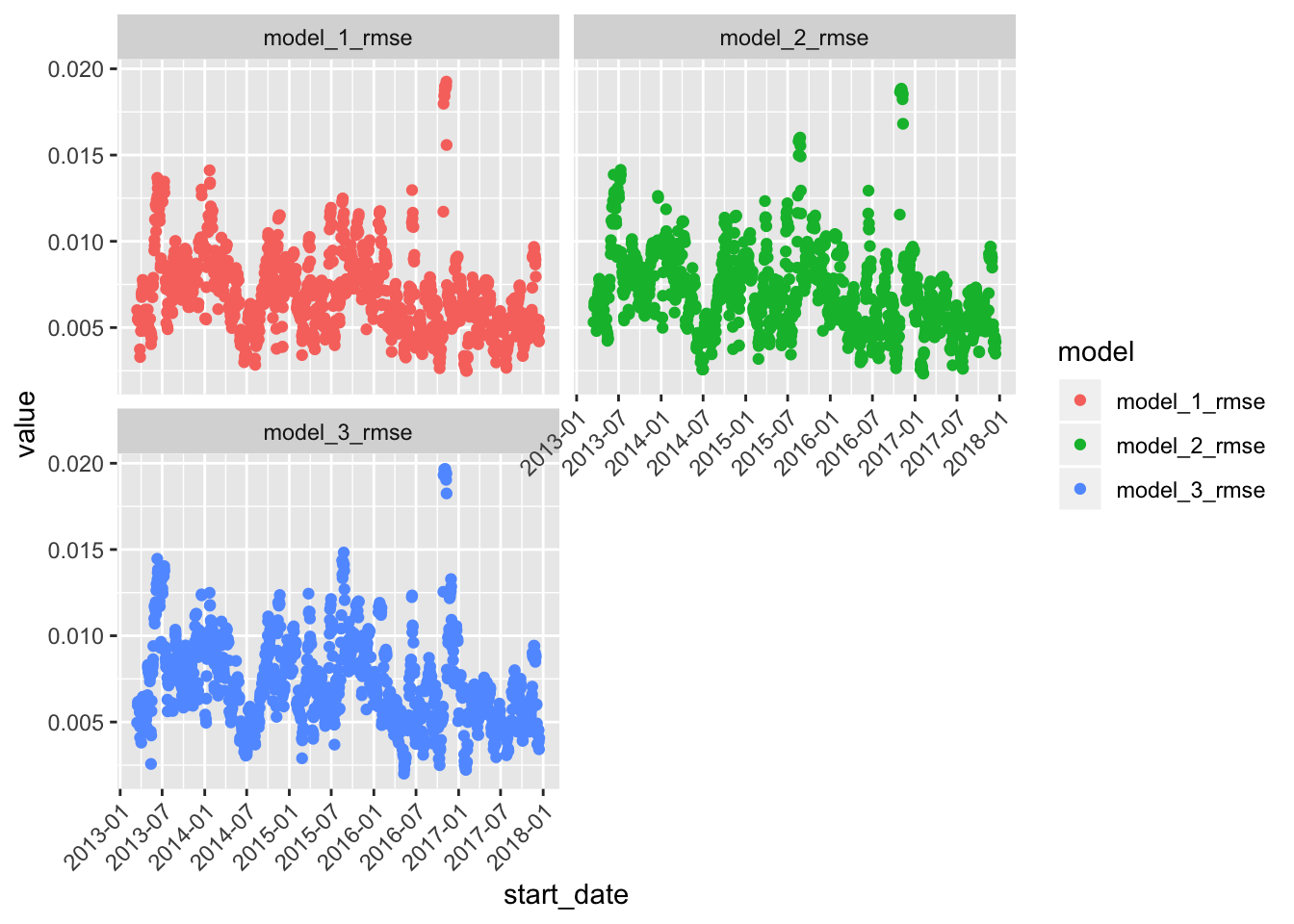
All of the models have a jump in RMSE, meaning they performed worse, around the end of 2017. We aren’t focused on the theory of these models today but if we were, this would be a good place to start investigating. This is just the beginning of our exploration of rolling_origin, but I love how it opens the door for ways to think about visualizing our models.
And finally, those same public service announcements from last time are still live, so I’ll mention them one more time.
Thanks to everyone who has checked out my new book! The price just got lowered for the holidays. See on Amazon or on the CRC homepage (okay, that was more of an announcement about my book).
Applications are open for the Battlefin alternative data contest and RStudio is one of the tools you can use to analyze the data. Check it out here. They’ll announce 25 finalists in January who will get to compete for a cash prize and connect with some quant hedge funds. Go get’em!
A special thanks to Bruce Fox who suggested we might want to expand on the Monte Carlo simulation in the book to take account of different distributions implied by historical returns and different market regimes that might arise. Today’s rolling origin framework will also lay the foundation, I hope, for implementing some of Bruce’s ideas in January.
Thanks for reading and see you next time.
You may leave a comment below or discuss the post in the forum community.rstudio.com.