Producing an API that serves model results or a Shiny app that displays the results of an analysis requires a collection of intermediate datasets and model objects, all of which need to be saved. Depending on the project, they might need to be reused in another project later, shared with a colleague, used to shortcut computationally intensive steps, or safely stored for QA and auditing.
Some of these should be saved in a data warehouse, data lake, or database, but write access to an appropriate database isn’t always available. In other cases, especially with models, it may not be clear where they should be saved at all.
Enter pins, a new R package written by Javier Luraschi. pins makes it easy to save (pin) R objects including datasets, models, and plots to a central location (board), and access them easily from both R and Python. Pins make it much easier to create production-ready R assets by simplifying the storage and updating of intermediate data artifacts.
Problems you can put a pin in
In general, pins are a good substitute for saving objects alongside analysis code as .csv or .rds objects. Especially when the object is reused several times or updated independently from the rest of the analysis, a pin is probably a better solution than saving a file with your code.
In this article, I’ll create a predictive model, programmatically serve predictions via a Plumber API, and visualize those predictions in a Shiny app. Along the way, I’ll make extensive use of pins for important parts of my workflow.
The model will predict future availability of bicycles at Capital Bikeshare docks, which provide short-term bicycle rentals in and around Washington DC. Capital Bikeshare makes data on the current availability of bikes at each station available via a public API.
I’m going to make model predictions available in production by providing programmatic access to the model via an API and to humans via a Shiny app. All of the code for this demo is available on Github.
To get there, I’m going to follow this analysis workflow:
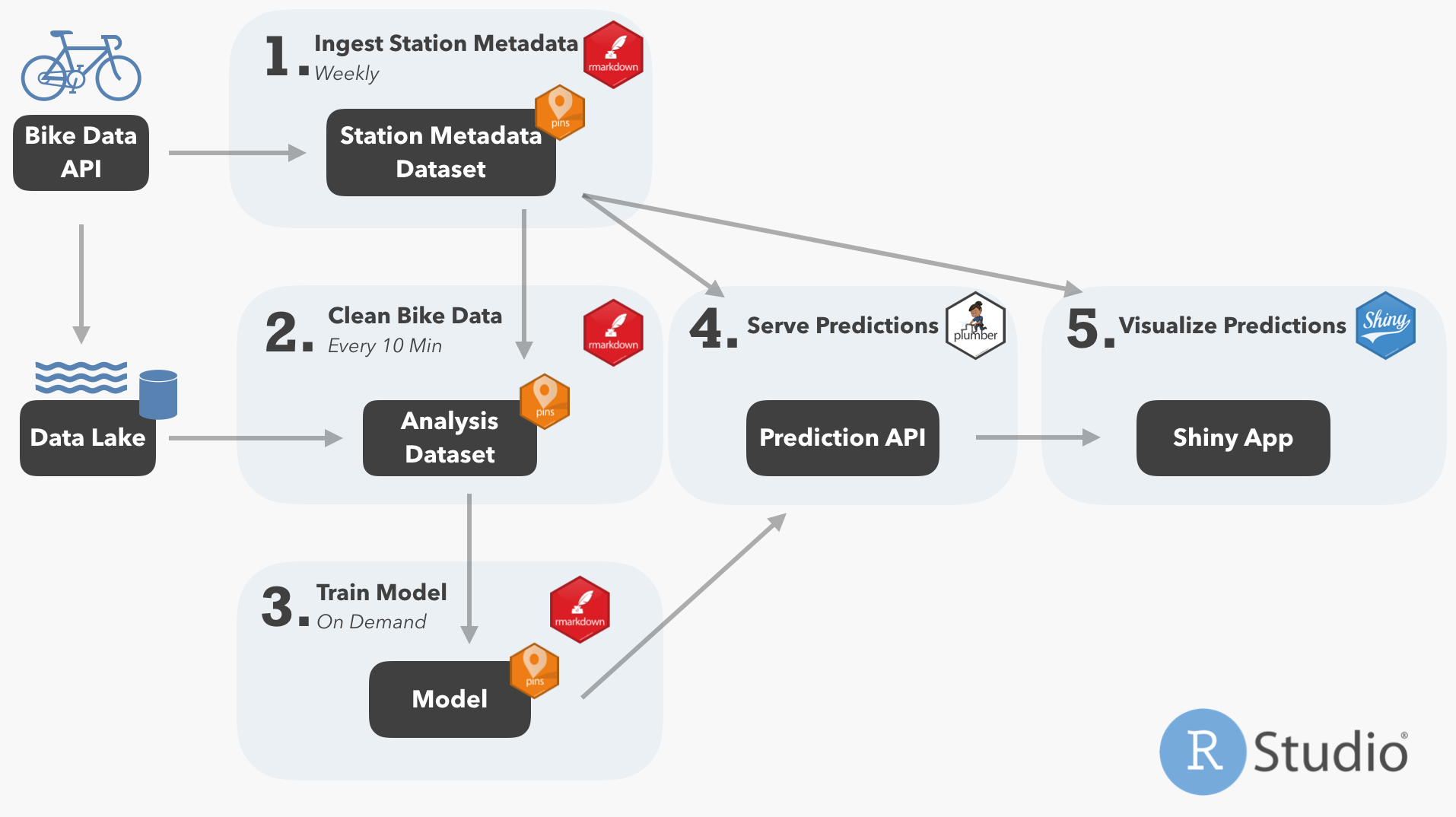
- Ingest metadata about the stations, like name and location, from the bike data API.
- Combine the station metadata with raw data on bike availability from the data lake to create an analysis dataset.
- Train and deploy a model of future bike availability.
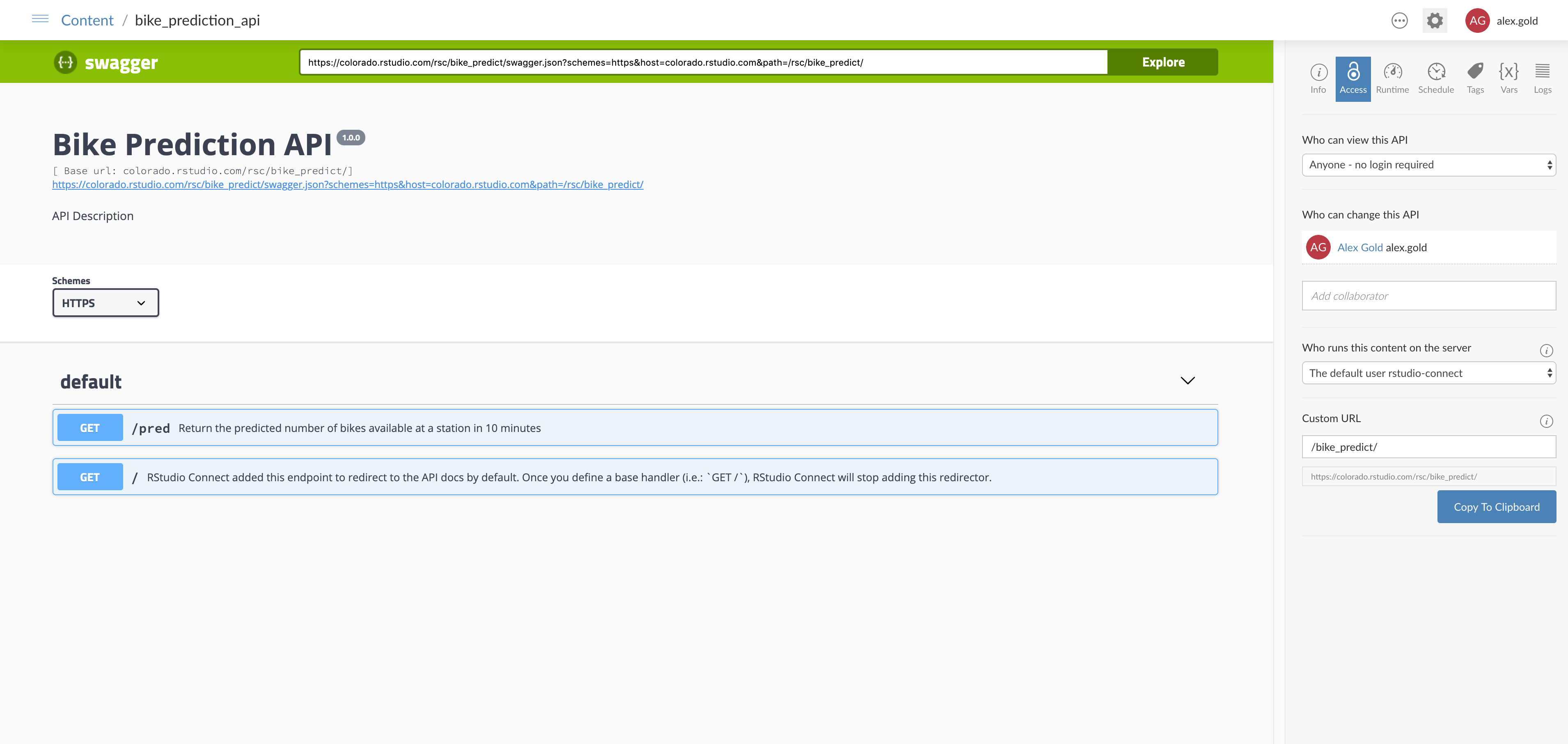
- Serve model predictions via a Plumber API.
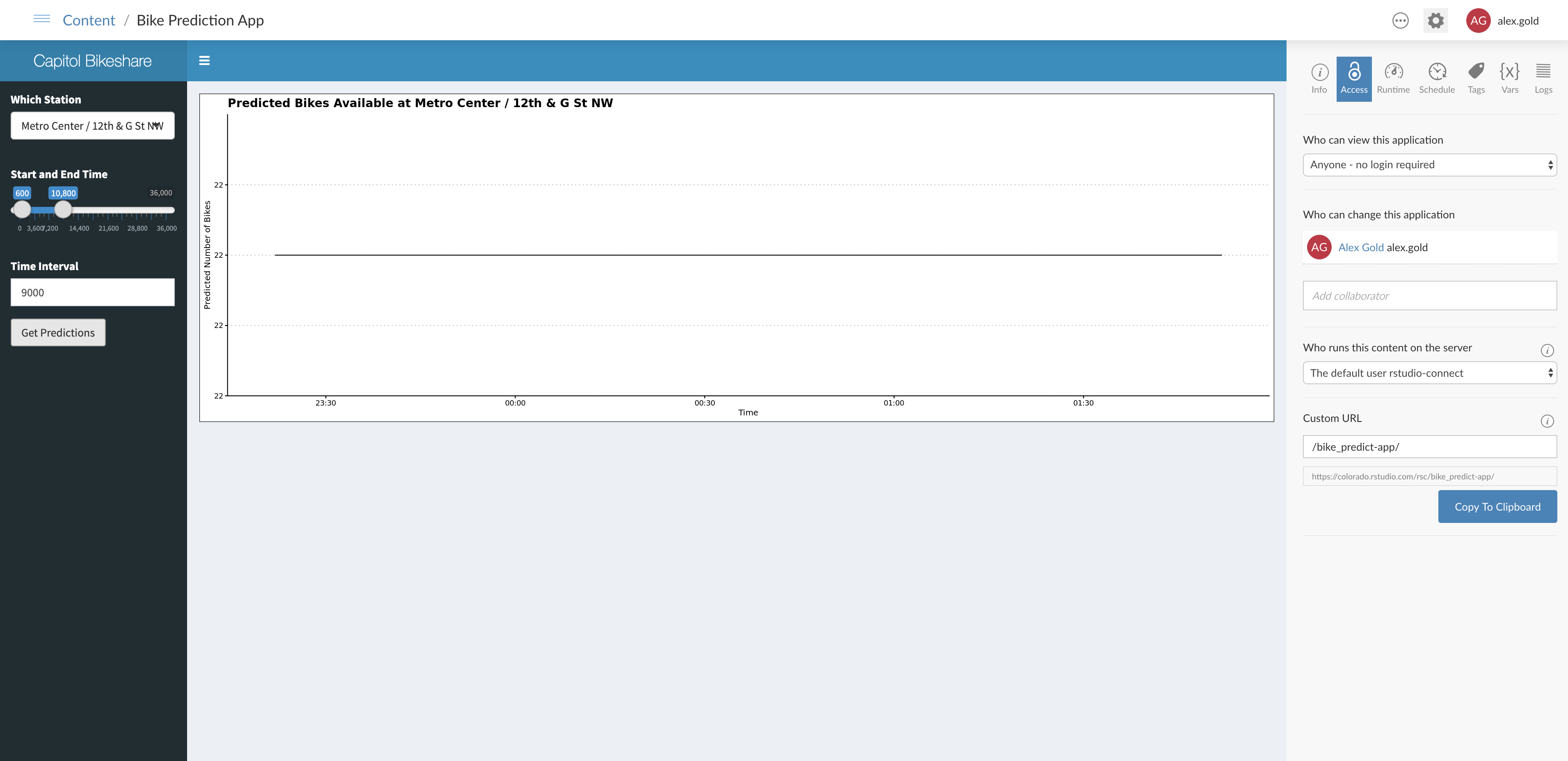
- Visualize model predictions via a Shiny app.
Along the way, here are three specific times that a pin is going to come in handy:
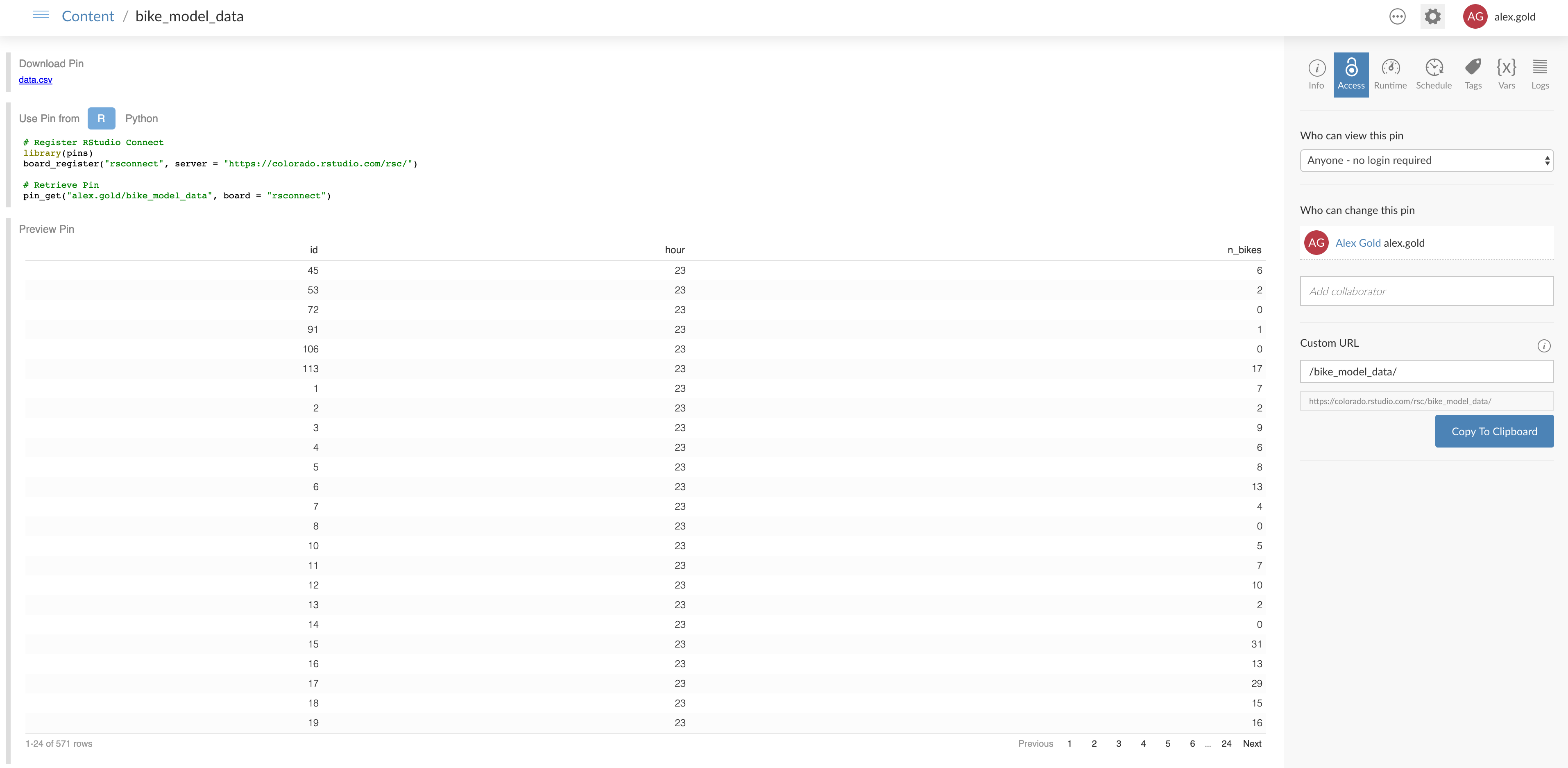
- Maintaining the metadata table of station IDs and details. Especially since I’m reusing this table in multiple assets in this project, having it in a pin is a sure way to know it’s up-to-date.
- Saving the final analysis dataset. In this case, the raw Capitol Bikeshare data is being imported with a completely separate ETL script, and I don’t want to write my analysis dataset into a data lake. Without a separate database for analysis data, a pin is my best option.
- Deploying the model to serve the predictions. Saving the model separately from the API makes it easy to decouple API and model versions and to retrain the model and redeploy seamlessly when needed.
In all of these cases, pins drastically simplify my workflow, improve discoverability of the objects my analysis has created, and makes me more confident that I’m always using the newest version.
Where to pin?
Before getting started describing exactly how this analysis project works, let’s dive a little deeper into the pins package itself.
Pins live on boards. A board is a set of content names and the associated files. The magic of the pins package is that with only two commands and the name of some content, you can upload and download your R objects without having to worry about how how the content is stored.
By default, there are two boards you can use immediately: the packages board of the datasets from R packages that are installed, and the local board, which caches datasets for quick loading later.
The real power of pins is unlocked with remote boards. pins supports Kaggle, Github, website, and RStudio Connect boards, and also supports building custom extensions. By using a remote board, you can use pins to make your R objects accessible to others on your team in a central location.
How it works
Using a pin works like this:
- Register the board with the the
pins::board_registerfunction. You’ll need to provide the proper authentication mechanism like a Kaggle token, Github Personal Access Token (PAT), or RStudio Connect API key if you are using a remote board.
For GitHub, you need a repo that you have write access to, as well as a token:
pins::board_register(board = "github",
repo = "akgold/pins_demo",
branch = "master",
token = Sys.getenv("GITHUB_PAT"))For an RStudio Connect board, you need the server URL and an API key:
pins::board_register(board = "rsconnect",
server = "https://colorado.rstudio.com/rsc",
key = Sys.getenv("RSTUDIOCONNECT_API_KEY"))At that point, your connections pane in RStudio will show the content available in the board.
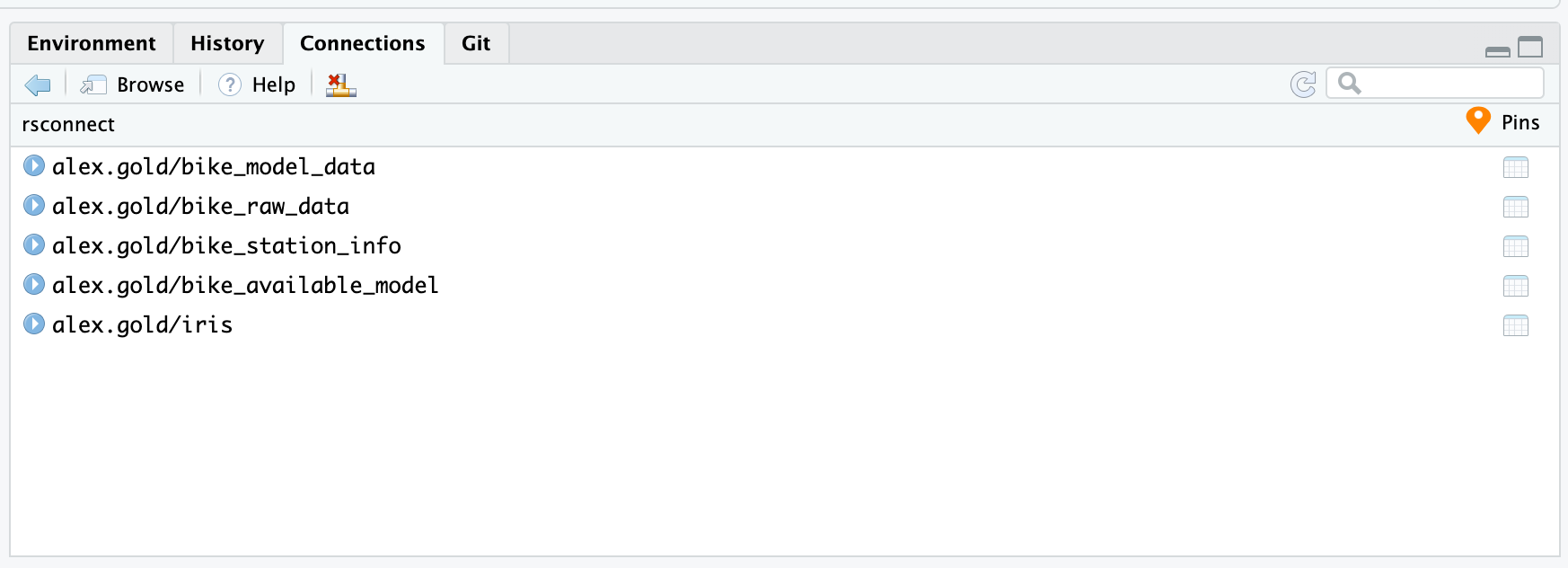
Once you’ve registered the board, your interactions are exactly the same no matter which board type you’re using.
- Pin an object to the board.
pins::pin(
x = mtcars,
name = "mtcars_pin",
description = "A pin of the mtcars dataset.",
board = "rsconnect"
)- Download the object later.
cars_data <- pins::pin_get(
name = "mtcars_pin"
board = "rsconnect"
)Production Apps with Pins
In order to create, serve, and visualize my bike-availability predictions, I’m going to use RStudio’s publishing and scheduling platform, RStudio Connect.
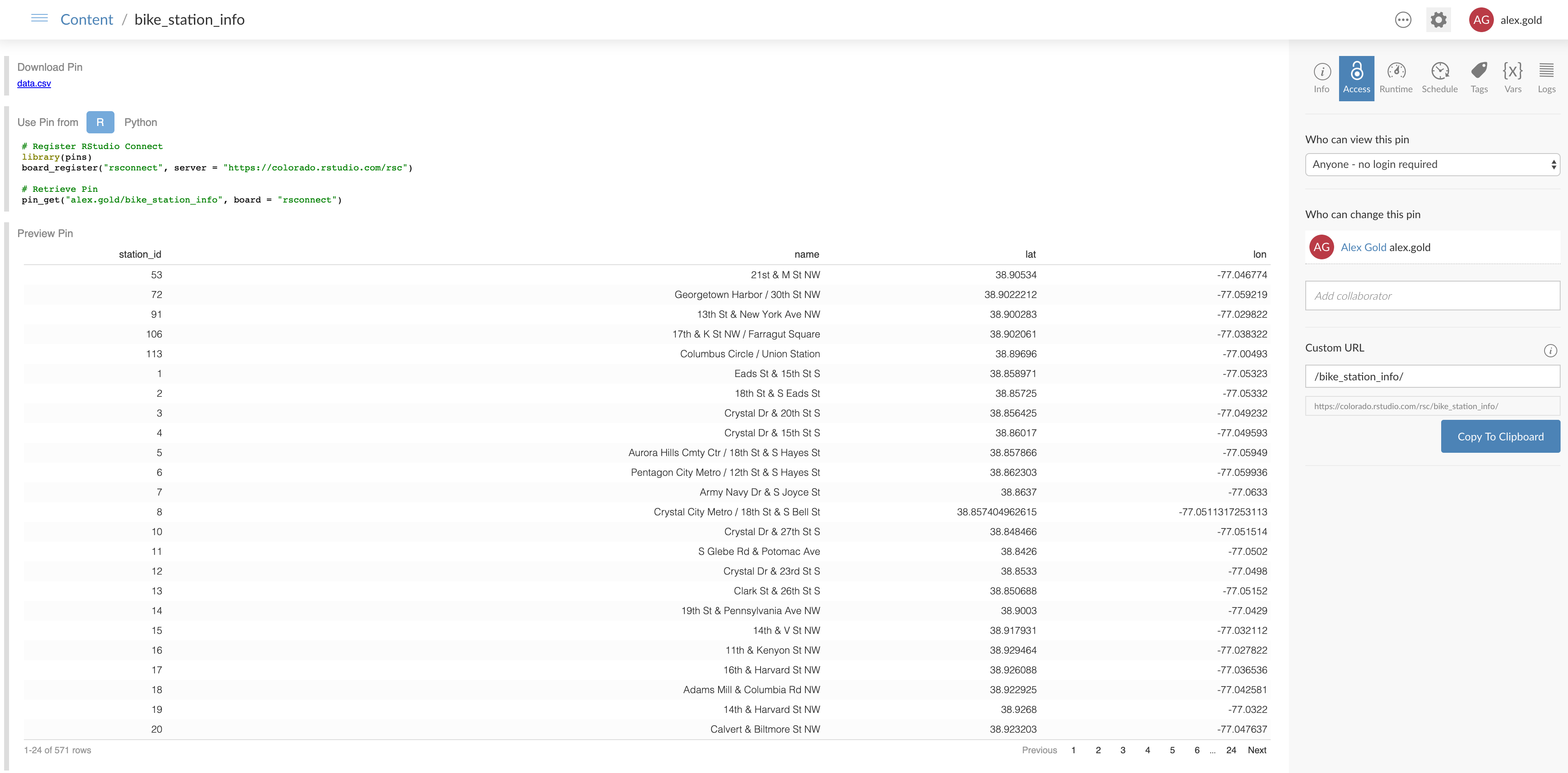
As of RStudio Connect 1.7.8, you can publish pins to RStudio Connect, and pins of datasets provide a nice preview of the pin, as well as code to retrieve the pin in both R and Python.
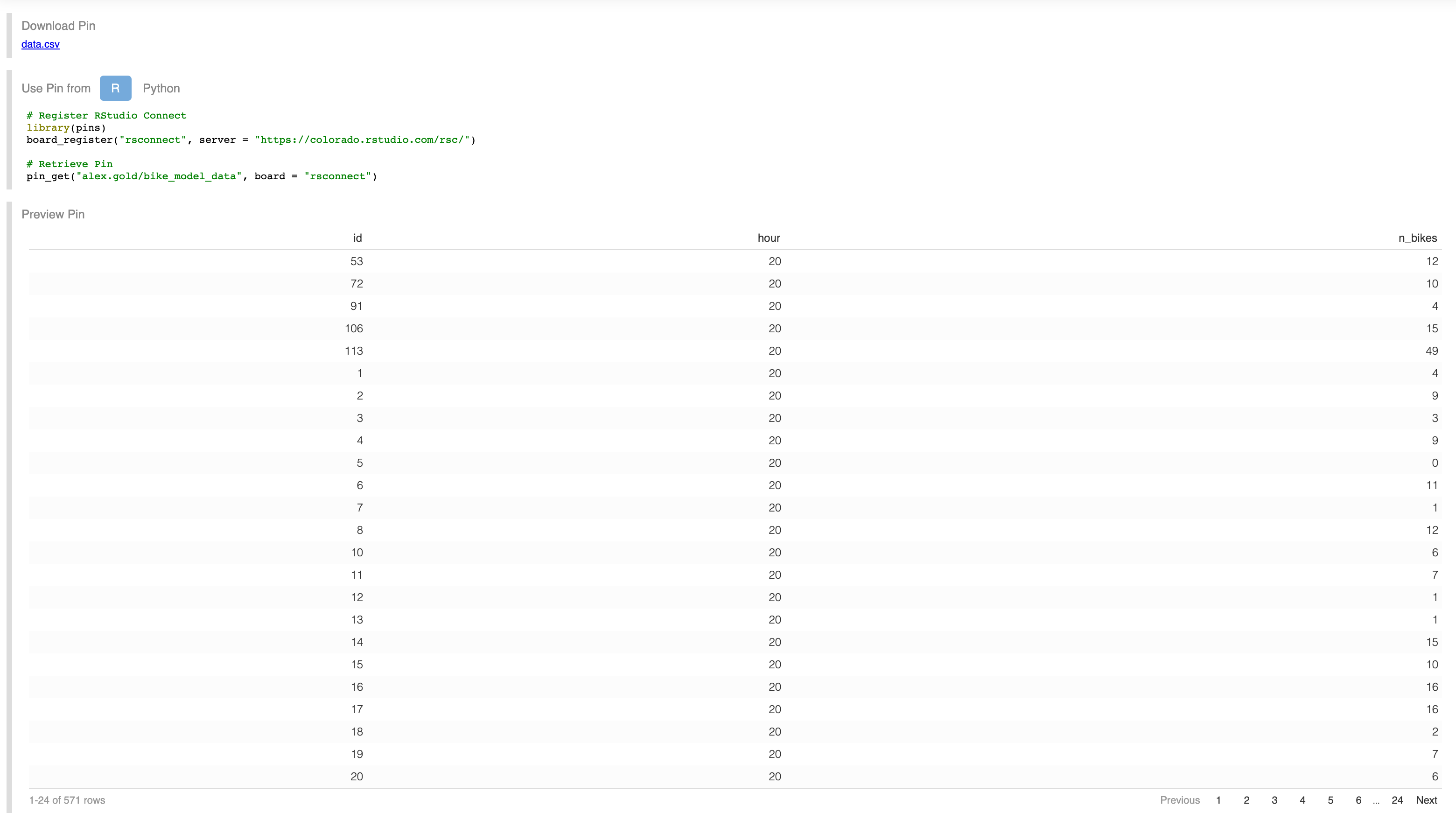
The advantage of using RStudio Connect is that I can deploy R Markdown documents, Shiny apps, and Plumber APIs that create, use, and update the pins in addition to storing the pins themselves. I can also use the permissions and security of RStudio Connect to make sure that my pins are viewable only by those with the proper permissions.
Here’s how the process works:
4.
5.
The three times that a pin was useful here turn out to represent three of the most compelling reasons to use a pin.
A small dataset that gets reused. By accessing the station metadata dataset in a pin, I know I’m always getting the latest version regardless of which asset is using it, and it’s also accessible for other analyses in the future.
An analysis dataset when you can’t write back to the database. In this case, I don’t want to write an analysis dataset back to the raw data lake, so it’s easier to store it as a pin.
A model in production. By using a pin to store my model, it’s easy to update the version that’s in production by running the R Markdown document that trains the model. It’s also conceptually simple to update the model independently from the API that serves predictions or the Shiny app that visualizes the predictions.
Pins can be a fantastic way to enable Shiny and Plumber in production. By giving data scientists a place to save and deploy the output of their projects, pins make it easier to create, deploy, and update models, datasets, and other production-ready R objects.
You may leave a comment below or discuss the post in the forum community.rstudio.com.